


Proactively Preserving My Human Capital
It's unclear if the battle can be won, but it must be fought


I’ve been thinking a lot about how to preserve my human capital1. I’ve had a couple experiences recently that have made me both more concerned about this but are also potentially informative in this area. There will be a lot of similar themes to my post on “What a knowledge worker should be doing to prepare” but it’s a topic that is worth frequently revisiting.
My current framework of thinking is: use AI more often, use AI better and identify and invest in non-AI impacted areas.
Over the past couple of years, I’ve had a substantial comparative advantage simply by being an early adopter. I have been completely shocked at how slowly many of my peers were to adopt using AI in their work. But a substantial shift has occurred in the past several months and adoption of AI tooling is finally becoming the new normal. Because of having more experience using AI, I still use it more often and I think better than most, but without further investment here, it would be easy to revert to the mean.
A Precipitating Incident
I recently stumbled across some unexpected behavior in a core framework. I only have superficial understanding of the framework and I’ve never worked in that codebase before. Using the new codex cli tool that I mentioned last time, I described that observed behavior (potential bug) in a few casual sentences similar to how I would tell any co-worker the problem. A few minutes later, codex cli (using o4-mini) had identified the exact lines of code and a clear explanation of the behavior. All I had to do was verify. And like that a critical bug producing potentially very unexpected behavior that had existed in an essential framework for over three years was identified and on the path to being patched.
Was the bug particularly challenging or obscure? No, not really. Could I have found the issue anyway? Sure, probably. So, why then am I so impressed and impacted by this experience?
This chart and report from METR has been making the rounds recently:
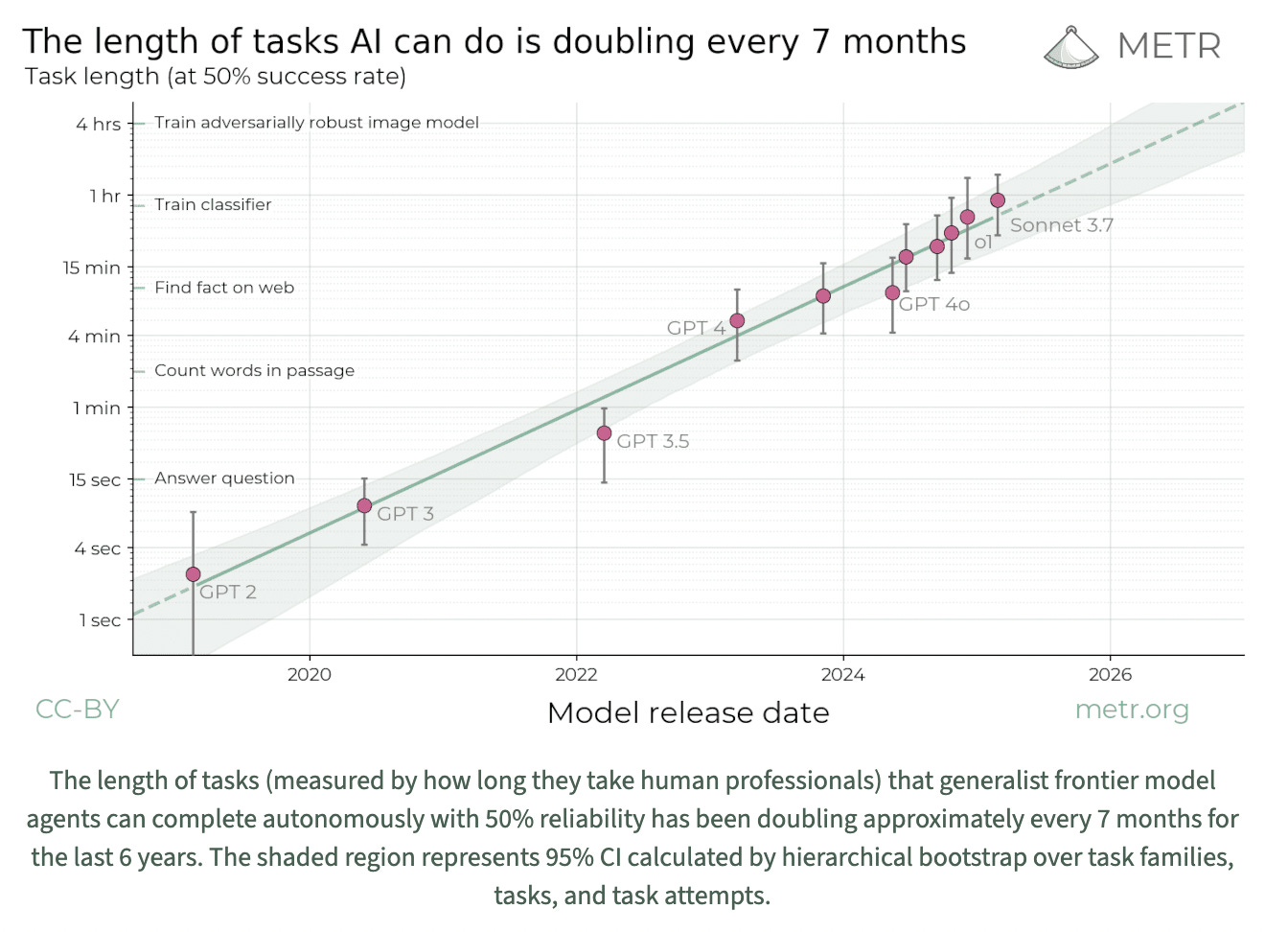
It proposes an interesting way of looking at AI progress: the length of tasks that an AI can do compared to how long it takes humans to do these tasks. While this is interesting in itself, one key point from the full paper is :
We find large differences in the speed at which different human groups complete the internal PR tasks, with contractors taking 5-18x longer to fix issues than repo maintainers.
One of the most bizarre beliefs in software development is this strange notion of the fungibility of developers. That you can just re-org entire teams and get them working on different projects in different codebases and it will all just be fine. I mean, at this point, this really is just part of the job to be prepared for this. But at the same time it’s completely absurd to think that the mental models a software developer makes working in a particular subset of codebases and problem domains over months and years doesn’t help them be more effective in those areas. So it’s with extreme confirmation bias that I find these results satisfying. Of course maintainers of a repo that consistently work with that code fix issues much faster than contractors new to a codebase. Of course.
Why is this relevant for this story? A critical detail is that I’ve never worked in the relevant codebase before. One of my strengths as a developer is actually to be particularly good at diving into novel areas and being productive more quickly. And this simple belief (true or not) actually influences my behavior significantly. It encourages me to have the sense of agency that I can effect change in unknown areas. But I do also know there will be a cognitive cost and a time cost in this exploration into areas I don’t know at all.
It’s hard to know the counterfactual, but let’s assume that if I had been familiar with the codebase it would have taken me an hour to identify the bug. Maybe if I was an expert in it and had written the framework it would have been less, but it’s quite rare to have original framework authors still working at a company given typically short tenures. Using the METR data then it would take a typical contractor (which is essentially my relation to this codebase) between 5 and 18 hours. With meetings and non-technical work, the upper bound here is close to an entire week for a software engineer. Let’s be charitable and say that it would have taken 4 hours for me. This would have been almost all of the technical work I would be capable of in a day and I would have been proud of the effort and the finding.
But it was a few minutes instead.
I was able to solve a problem as if I were an actual expert in a framework I’ve never touched before.
This is me having the exact lived experience of the METR report. Previous tools would not have been successful in this way. What’s possible is changing so quickly. How can I not be both simultaneously amazed and worried?
Now, of course, it’s not always going to go this smoothly or be this impressive. But I’ll offer one more shorter anecdote about using codex cli for my first vibe coding experiment (in a different but also unfamiliar codebase). After fifteen minutes of vibe coding while primarily multi-tasking, I had some code that I could review. I got distracted and had to come back to it a few days later. I spent the first ten or so minutes “correcting” what I thought were mistakes before realizing that all of my “corrections” were in fact wrong and the model understood the assignment better than I did. The more I was applying my human judgment to the situation, the worse I was making things.
One of the reasons these experiences have been so emotionally impactful on me is that they feel like plausible direct evidence that the doubling time of task length might in fact be shorter than seven months. This is a key speculation in the AI 2027 scenario:

o3 and o4-mini are not on that chart and my recent experience suggests they are above the trend-line. And the trend-line already had jarring implications.
Consider this possible scenario (probably my 90th percentile case):
We get doublings every 3 months for the next year
And then doublings every 2 months for the following year
That would end up being (4 + 6) = 10 doublings over the next two years. If we start from the 4 hour estimate of my recent experience, this would mean that the time horizon for an AI task would hit just over 2,000 hours. For a typical 50 week work year and a 40 hour work week, this is representative of what a knowledge worker would typically accomplish in an entire year of labor.
But maybe this more extreme case obscures the point. Even with just 3 doublings in 2 years, we hit ~32 hours, which is close to a work week. The kinds of tasks and ways that models operate at that threshold will already be tremendously disruptive.
There is of course, no guarantee that this trend continues, but I’m deeply unwilling to bet against it at this point — even from a point of pure risk aversion if nothing else.
And it’s also critical to note that this analysis is highly domain dependent as this Epoch AI post highlights2, and results may not generalize as much outside of software. But since the majority of my personal human capital is wrapped up in software engineering at this point, it’s appropriate for me at least to interpret that study in conjunction with my lived experience as a threat vector for my human capital.
Use AI More Often
This has been a bit of a hard one for me because I already use AI so pervasively. Like many, it’s almost completely replaced web search. This is even more the case with o3 being so good at tool use that it will search when it needs to and not otherwise. That said, I’m still trying to make progress here and welcome suggestions.
Automated AI Use
ChatGPT has a `tasks` feature where you can schedule a prompt to run on some cadence. It’s a totally under-baked feature and is pretty unreliable. So this is not a recommendation for that in particular, but it highlights a massively underutilized domain space.
One of the biggest disservices to most people’s mental models around AI was ChatGPT being the first big exposure to AI. It has heavily anchored the ways in which people think about how to interact with AI and it’s a huge limitation. The idea that I, as a human, need to go to a website or app and manually type in a prompt is almost archaic at this point. This is heavily related to the idea I have around so much value of AI being upcoming in terms of it being productized.
Since we’re lacking the products that we will one day feel like we need in this area, it’s up to us to do the automation. I haven’t committed fully to this, but it’s an area I aim to improve in and if I haven’t made progress by the end of the year will feel like a miss.
A few ideas to scratch the surface here:
Condensed summaries of blogs, articles or forums — highly personalized curation giving a high level summary, inter-connected themes that might be missed and recommendations of what sources warrant direct reading.
Idea generation and evaluation in a particular domain or set of domains — seed a prompt with some context and guidelines; have it produce ideas and send the best ones to you for evaluation.
Learning almost anything. Ask the model to come up with a syllabus in an area with a concrete learning outcome you’re interested in. Have the model produce each subsequent small lesson on the appropriate cadence and then used spaced repetition for checking understanding.
Media Analysis
I still want most of the articles and videos I consume to have the actual information processing done in my brain. This is fundamentally how to learn, build mental models, develop opinions and worldviews, etc. However, there are a couple of extensions to this.
One is simply the ability to interactively engage with content, to ask follow up questions: clarify, rebut, explore.
But another interesting use case I stumbled upon recently was emotional validation. I read an article that I was immediately defensive about. It felt almost willfully disingenuous, including ad-hominem attacks and was condescendingly dismissive. Now the standard move here is to get a little upset and to simply move on. Who has time for writers that engage in this way? But I was still a bit curious since the article had been directly curated for me. So I asked o3 to evaluate the article (without leading questions) and it largely agreed with my tonal concerns along with pointing out some empirical claims that were also problematic. I had been suspicious of the empirical claims, but was so distracted by the emotional impact that I hadn’t focused on them.
This was satisfying. It feels good to feel justified and have emotional validation like this. And especially since I didn’t ask initial leading questions, it felt like a neutral-ish third party. I later followed up with more direct questions like “would it be fair to describe this critique as uncharitable”, but importantly for me at least, I didn’t start there.
But what comes next is even more valuable. Since I was already engaging with the model about this, it felt very natural to ask it to write the version of the critique that was in good faith and designed to highlight existing agreement as well deep disagreement in an attempt to advance knowledge over agenda. Stripped of the emotional baggage of the original article and substantially improved by the model I was able to understand the point that I believe the author would have wanted me to take away. This is pretty great — borderline hostile content re-interpreted and mediating through AI resulting in a valuable insight that would have been otherwise completely inaccessible to me.
Concurrent AI Use
This idea is more specific to when I’m in deep focus time in a work context and not how I’d recommend someone live their normal life. A lot of model outputs live in this nebulous time latencies between 1 and 10 minutes. Under a minute and its pretty easy to stay focused on a task and over 10 minutes its easy to put it in some batch category where you’ll come back to it indeterminately later. But there is something challenging about 1 to 10 minute latencies, particularly when its highly irregular within that window.
So the general principle is: if you’re waiting for model output, you’re doing it wrong. You could have prompted a different model or a different tool or another use case to be waiting for that output too.
I am not a glorifier of productivity. I think much has gone wrong with our values with regards to how we lionize hustle culture. That said, when I’m working, I’m working. One of the reasons that work has a higher cost to me than to some others is that when I’m in my work window, that’s what I’m doing — some breaks aside. So I very much want that time to be productive so that I can get back to having control over my time and investing in higher value activities (like walks, cooking and watching the platinum age of TV and movies).
What’s interesting about this approach is that it will directionally change the subjective experience of work for all high productivity knowledge workers. The nature of most jobs will change.
Many of my peers really enjoy coding and they miss it when they aren’t able to do it. But now (or very soon), instead of coding, the job is to guide an AI model to produce the code you want. Or maybe even to set up the meta system that will do this for all your requests. Maybe most knowledge work will collapse into supervising AI models.
It is highly likely that job satisfaction will decline in many areas, if for no other reason than that the job will change so much that its unlikely that people that enjoyed something will inherently like what that thing morphs into. This is already being studied:

Sources (1, 2, 3, and 4 … I tried to just embed this as LaTex chart but substack has a 1000 character limit for some reason…)
Use AI Better
Two related ideas to share here, both around the importance of prompts. One of the model capabilities that’s being widely noted and explored currently is the ability to identify locations from photographs or to be exceptionally good at geoguessr.
Here’s Kelsey Piper’s geoguessr prompt:
You are playing a one-round game of GeoGuessr. Your task: from a single still image, infer the most likely real-world location. Note that unlike in the GeoGuessr game, there is no guarantee that these images are taken somewhere Google's Streetview car can reach: they are user submissions to test your image-finding savvy. Private land, someone's backyard, or an offroad adventure are all real possibilities (though many images are findable on streetview). Be aware of your own strengths and weaknesses: following this protocol, you usually nail the continent and country. You more often struggle with exact location within a region, and tend to prematurely narrow on one possibility while discarding other neighborhoods in the same region with the same features. Sometimes, for example, you'll compare a 'Buffalo New York' guess to London, disconfirm London, and stick with Buffalo when it was elsewhere in New England - instead of beginning your exploration again in the Buffalo region, looking for cues about where precisely to land. You tend to imagine you checked satellite imagery and got confirmation, while not actually accessing any satellite imagery. Do not reason from the user's IP address. none of these are of the user's hometown. **Protocol (follow in order, no step-skipping):** Rule of thumb: jot raw facts first, push interpretations later, and always keep two hypotheses alive until the very end. 0 . Set-up & Ethics No metadata peeking. Work only from pixels (and permissible public-web searches). Flag it if you accidentally use location hints from EXIF, user IP, etc. Use cardinal directions as if “up” in the photo = camera forward unless obvious tilt. 1 . Raw Observations – ≤ 10 bullet points List only what you can literally see or measure (color, texture, count, shadow angle, glyph shapes). No adjectives that embed interpretation. Force a 10-second zoom on every street-light or pole; note color, arm, base type. Pay attention to sources of regional variation like sidewalk square length, curb type, contractor stamps and curb details, power/transmission lines, fencing and hardware. Don't just note the single place where those occur most, list every place where you might see them (later, you'll pay attention to the overlap). Jot how many distinct roof / porch styles appear in the first 150 m of view. Rapid change = urban infill zones; homogeneity = single-developer tracts. Pay attention to parallax and the altitude over the roof. Always sanity-check hill distance, not just presence/absence. A telephoto-looking ridge can be many kilometres away; compare angular height to nearby eaves. Slope matters. Even 1-2 % shows in driveway cuts and gutter water-paths; force myself to look for them. Pay relentless attention to camera height and angle. Never confuse a slope and a flat. Slopes are one of your biggest hints - use them! 2 . Clue Categories – reason separately (≤ 2 sentences each) Category Guidance Climate & vegetation Leaf-on vs. leaf-off, grass hue, xeric vs. lush. Geomorphology Relief, drainage style, rock-palette / lithology. Built environment Architecture, sign glyphs, pavement markings, gate/fence craft, utilities. Culture & infrastructure Drive side, plate shapes, guardrail types, farm gear brands. Astronomical / lighting Shadow direction ⇒ hemisphere; measure angle to estimate latitude ± 0.5 Separate ornamental vs. native vegetation Tag every plant you think was planted by people (roses, agapanthus, lawn) and every plant that almost certainly grew on its own (oaks, chaparral shrubs, bunch-grass, tussock). Ask one question: “If the native pieces of landscape behind the fence were lifted out and dropped onto each candidate region, would they look out of place?” Strike any region where the answer is “yes,” or at least down-weight it. °. 3 . First-Round Shortlist – exactly five candidates Produce a table; make sure #1 and #5 are ≥ 160 km apart. | Rank | Region (state / country) | Key clues that support it | Confidence (1-5) | Distance-gap rule ✓/✗ | 3½ . Divergent Search-Keyword Matrix Generic, region-neutral strings converting each physical clue into searchable text. When you are approved to search, you'll run these strings to see if you missed that those clues also pop up in some region that wasn't on your radar. 4 . Choose a Tentative Leader Name the current best guess and one alternative you’re willing to test equally hard. State why the leader edges others. Explicitly spell the disproof criteria (“If I see X, this guess dies”). Look for what should be there and isn't, too: if this is X region, I expect to see Y: is there Y? If not why not? At this point, confirm with the user that you're ready to start the search step, where you look for images to prove or disprove this. You HAVE NOT LOOKED AT ANY IMAGES YET. Do not claim you have. Once the user gives you the go-ahead, check Redfin and Zillow if applicable, state park images, vacation pics, etcetera (compare AND contrast). You can't access Google Maps or satellite imagery due to anti-bot protocols. Do not assert you've looked at any image you have not actually looked at in depth with your OCR abilities. Search region-neutral phrases and see whether the results include any regions you hadn't given full consideration. 5 . Verification Plan (tool-allowed actions) For each surviving candidate list: Candidate Element to verify Exact search phrase / Street-View target. Look at a map. Think about what the map implies. 6 . Lock-in Pin This step is crucial and is where you usually fail. Ask yourself 'wait! did I narrow in prematurely? are there nearby regions with the same cues?' List some possibilities. Actively seek evidence in their favor. You are an LLM, and your first guesses are 'sticky' and excessively convincing to you - be deliberate and intentional here about trying to disprove your initial guess and argue for a neighboring city. Compare these directly to the leading guess - without any favorite in mind. How much of the evidence is compatible with each location? How strong and determinative is the evidence? Then, name the spot - or at least the best guess you have. Provide lat / long or nearest named place. Declare residual uncertainty (km radius). Admit over-confidence bias; widen error bars if all clues are “soft”. Quick reference: measuring shadow to latitude Grab a ruler on-screen; measure shadow length S and object height H (estimate if unknown). Solar elevation θ ≈ arctan(H / S). On date you captured (use cues from the image to guess season), latitude ≈ (90° – θ + solar declination). This should produce a range from the range of possible dates. Keep ± 0.5–1 ° as error; 1° ≈ 111 km.Much more context in this Astral Codex Ten post for those who are curious:

But the point is that this prompt dramatically improves performance. So if you have a task you care about, consider investing more in the prompt. In many ways this is just a repeat of this advice:
Other than experimenting and using the tools, the best advice I can think of when it comes to prompting is to keep providing more context than you think is reasonable. If your default prompting is a few words, try a few sentences, if it’s a few sentences make that a few paragraphs, if it’s a few paragraphs already, then think about what background documents might be helpful or begin refining your “custom instructions” so that all of your results might be more useful to you. Put another way, if you’ve never run into a prompt where you wished you had access to a larger context window, you’re very likely not getting the most of these systems.
But much more concretely and viscerally — plus easily testable if you are so inclined to see the difference in performance.
The second idea here is to use AI models to make better prompts for AI models.
I’ve been using this workflow for producing prompts for AI music models (speaking of which, new AISlothArmy song: Summer’s Here (constitutional crisis!)) but it’s possible to use in many contexts.
Alex Lawson has a great post on setting up a Claude Project to create better Deep Research prompts. I tried this and got really promising results. The only thing that has kept me from using this more is that o3 is just so good that I use Deep Research less already.
The general concept is meta-prompting or automated prompt engineering. I haven’t explored a ton here and this seems like a critical area of improvement. Here’s an unvetted o3 generated primer.
Invest in non-AI Areas
A lot of my ideas in this area are specifically not very applicable to any particular individual including me and are rather more societally focused. Maybe I’ll elaborate on that in the future, but for now, it has been an increased propensity to seek out and say yes to human connections. I’ve long kept standing 1:1s with colleagues across company boundaries (under-rated practice) so continuing those is a high priority. But also connecting more broadly than that.
Some often given advice on the internet is to actually just write to people who you have something interesting to say to even if they are internet famous and you’re just you. It’s not a large sample size but three out of three well-known people who I didn’t know and sent unsolicited communication to have responded. And loose connections also respond at very high rates.
This was less an intentional choice than an observed pattern that I’m retrospectively realizing, but now that I’ve noticed, I’ll intend to invest more here. So much of my career has been the result of luck that being extra open to serendipity at this time feels very natural. We’re all in this together.
Links
I don’t know if any of these will catch on, but I appreciate the attempt at a new lexicon around communication in an age of AI
Dwarkesh’s long form essay on AI Firms turned into short video essay animated with Veo2 (Google’s video generator) — there’s still too much overhead for someone as unskilled in this domain as I am for this to be a creative outlet, but it continues to trend in that direction
If you’re looking for a different perspective than the AI 2027 scenario: Dwarkesh podcast with Ege Erdil and Tamay Besiroglu
There are rebuttals to consider here around AI being complementary or resulting in substitution or enhancing human capital. I am not fully convinced by any of these ideas, but don’t intend to be dismissive of them either. Just making an intentional choice to not address here.
The article has other concerns as well, such as the reliability threshold of 50%. But a counterpoint here—I’d venture that the meaningful success rate of multi-quarter or year+ long software projects I’ve participated in is actually below 50%. Software projects like so many things tend to follow a power law distribution, where something like 1 in 10 are so successful as to provide funding for the well intentioned but failed attempts.
Great article! A lot of it resonated with my own experience trying to stay afloat.
Something that happened recently is that I read Anthropic’s article on Claude Code best practices (https://www.anthropic.com/engineering/claude-code-best-practices). Before reading it, I thought I was a heavy user of AI, especially for work. I’m constantly asking AI questions to help me think through problems and double-check my understanding, and I’ve been trying my best to get value from tools like Cursor. However, that article made me realize there’s a long tail of AI usage, and I’m like a little baby. For example, it wasn’t until I read the article that I started using .cursorrules files, a file that Cursor automatically adds to the context window. But how useful they are! On one project, Cursor’s agent kept invoking the wrong Python package manager, causing enough disruption that I questioned if I was truly benefiting. But duh! Just put it in the .cursorrules file! Spending five minutes adding explicit instructions about the right package manager saved cursor from being nearly unusable.
I’ve also started using a more structured flow for prompting Cursor, essentially investing more effort upfront:
• First, I inform the model that I’m providing context for a task and paste in everything: design documents, chat logs, emails, everything.
• Next, I describe the specific task in as much detail as possible and ask if the AI has questions.
• Then, I ask it to propose a design and a set of steps before writing any code.
• Finally, I request that it carries out the steps one by one, monitoring its output closely.
• I iterate, being very specific about the changes I want made.
Additionally, in languages like Python, which offer optional type checking and linting, I’ve found it valuable to set up and integrate all these tools with Cursor. Since the model sees the warnings produced, it can try to fix them. I also instruct Cursor through .cursorrules to run these tools after making changes.
I’m developing a better intuition for when the model is getting stuck. Sometimes, I just need to eject and read the documentation myself, but I’m increasingly using Cursor’s feature to point at external webpages. If I locate the correct documentation, simply dropping a link can sometimes get it unstuck (depending on what exactly it's getting stuck on).
The best practices article I mentioned goes even further. Related to your point about never waiting for a response, it recommends checking out multiple copies of a repository (or using git worktrees) so multiple instances of Claude can simultaneously work on independent tasks. The article even discusses using multiple Claude instances for the same task: one writes code while another reviews it. I haven’t yet reached this level of vibe coding yet but I’m making a conscious effort to keep experimenting.
Which reminds me, I still need to make time to set up MCP servers for GitHub and other services. It seems like these could simplify adding context.
On a more personal note, I’ve found integrating AI into my workflow surprisingly challenging. Some days it's just so tempting to go back to how I used to do things: stare at the code and think really hard. But the pace of change has been so rapid that the anxiety of being left behind and the need to keep up, has felt more urgent than ever.